Nanyang Technological University, Singapore
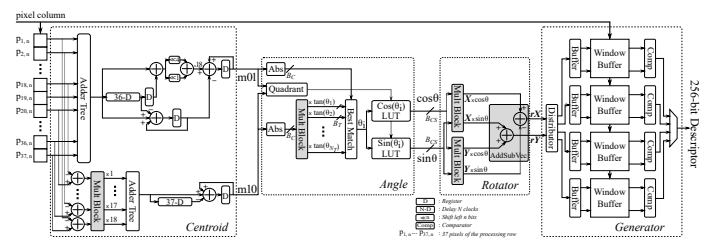
Figure 1. shows the rBRIEF feature extractor consisting of four units, i.e. Centroid, Angle, Rotator, and Generator.
The Centroid unit is used to compute the moments (i.e. m01, m10) of a key-point’s patch as in Eq. (1). $$ \begin{align} \tag{1} \begin{split} m_{01} = \sum_{x,y} y \times p_{x,y}, \\ m_{10} = \sum_{x,y} x \times p_{x,y} \end{split} \end{align} $$
The Angle unit calculates the orientation angle of the patch based on the values of the moments.
The Rotator unit uses the orientation angle from the Angle unit to rotate the coordinates of the pre-determined BRIEF point-pairs as in Eq. (2). The rotated coordinates of the BRIEF point-pairs are used to access the corresponding pixel intensities in the window buffer. $$ \begin{align} \tag{2} \begin{bmatrix} rx \\ ry \end{bmatrix} = \begin{bmatrix} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} \end{align} $$
The Generator unit fetches the pixel intensities of the rotated BRIEF point-pairs from the window buffer to generate the description bits as in Eq. (3). $$ \begin{align} \tag{3} \tau(p;a;b):= \begin{cases} 1 &\text{if} \; p(a) < p(b) \\ 0 &\text{otherwise} \end{cases} \end{align} $$
The proposed rBRIEF feature extractor is designed with a low-complexity deep-pipelined architecture. The proposed hardware-efficient strategies enable additional pipeline stages to be introduced in the computation units (i.e. 5 stages for Centroid unit, 5 stages in Angle unit, and 9 stages in Rotation unit) to increase throughput, while still achieving significantly reduced area utilization.
In the Angle unit, an approximation is applied to calculate the centroid angle of a patch centered at a key-point. The centroid angle is discretized into NT possible values and the multiplication of discretized angle values are represented with BT bits. We have used Displacement and Hamming distance to evaluate the effects of our approximation methods for the proposed rBRIEF feature extractor. Displacement in rotated coordinates between the actual calculation and the approximate calculation is employed to quantitatively evaluate the accuracy of the approximation. Hamming distance, which is a metric that is often used in feature matching, is employed to validate the effect of the approximation method on the final output descriptors. The Displacement is defined as follows:
$$ \begin{align} \tag{4} \text{Displacement} = \sqrt{(rx - rx_{ac})^2 + (ry - ry_{ac})^2} \end{align} $$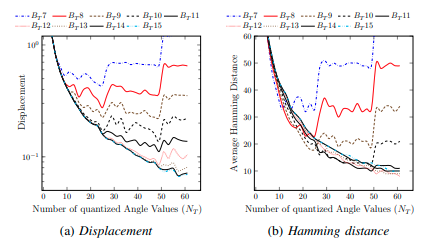
Figure 2 shows the accuracy evaluation of angle discretization with respect to \(N_T\) (number of discretized values of angle) in terms of (a) Displacement and (b) Hamming distance. \(B_T\sharp n \) denotes n bits that are used to represent the discretized angle values. It can be observed that Displacement is significantly reduced when \(N_T\) increases to 25. Hamming distance has the same trend but presents small variation.
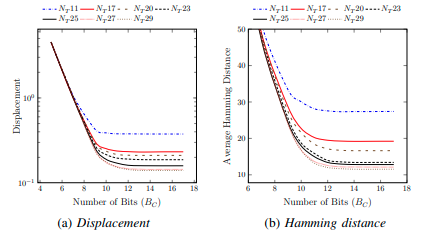
The optimal number of bits \(B_C\) for representing centroid moments is also investigated. Figure 3 shows (a) the Displacement and (b) the average Hamming distance of approximate calculation with respect to varying number of bits used for representing the absolute value of centroid moments (i.e. m01, m10). The displacement is also reported with different angle discretization options. \(N_T\sharp n \) denotes that the angle is discretized with \(N_T = \sharp n \) values. It can be observed that the average displacement sharply increases when BC reduces below 9.
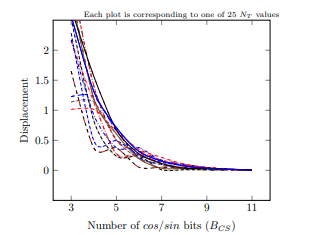
In addition, the optimal bit-width of \(\cos \theta \), \(\sin \theta \) values (i.e. \(B_{CS}\)) is investigated to further reduce the hardware complexity of the the Rotator unit. This study is based on the optimal discretization of the centroid angle \(N_{T}\) = 25 which we have determined earlier. Figure 4 illustrates the average coordinate displacement with varying \(B_{CS} \) with respect to each \(N_{T}\) .The displacement for each \(N_{T}\) rapidly decreases as BCS increase to 7. The displacement of all the 25 cases is below 0.25 if \(B_{CS}\) = 7 bits is employed to represent the cosθ, sinθ values. Further increase in \(B_{CS}\) does not lead to any notable displacement reduction. Therefore, \(B_{CS}\) = 7 is selected for the proposed architecture.
Table I summarizes the design parameters and compares the hardware utilization of the proposed implementation (denoted as Proposed) with the implementation in [1] (denoted as Existing). To obtain a fair comparison, both implementations targets the Arria V GX 5AGXFB3 device and employ the same number of descriptor generator components \(N_{D}\). It can be observed that the proposed implementation consumes significantly reduced number of Logic Elements (LEs) and Adaptive Logic Modules (ALMs) compared to the existing implementation. The LE and ALM utilization of Proposed is only 63.5% and 46.7%, respectively, of the existing architecture. The memory bits usage of Proposed is larger than that of Existing. However, the memory bits required in both implementations consume only a fraction (i.e. about 0.6%) of the total FPGA space. Interestingly, the proposed implementation avoids the use of power-hungry DSP blocks due to utilization of the constant multiplier blocks. In contrast, the existing implementation employs 92 DSP blocks. Furthermore, the hardware efficient strategies adopted by Proposed have resulted in a higher maximum clock frequency. In particular, Proposed achieves a higher operating frequency of 177 MHz compared to the clock frequency of 150 MHz for Existing on the same target FPGA platform
[1] J. Weberruss, L. Kleeman, D. Boland, and T. Drummond, “FPGA Acceleration of Multilevel ORB Feature Extraction for Computer Vision,” in 27th International Conference on Field Programmable Logic and Applications (FPL), Sep. 2017
Link to the latest version paper
This research project is partially funded by the National Research Foundation Singapore under its Campus for Research Excellence and Technological Enterprise (CREATE) programme.
For any questions regarding the publications, please contact me or post a comment below and I will respond shortly.