Methods
1. Architecture
We used DQN for training a policy to output actions given the image inputs. We give the agent high exploration rate
at the beginning of training. Hence, the agent takes a random action and stores its
transition to a memory buffer for multiple episodes most of the time. This memory
buffer stores all the most recent transitions that an agent took up to a maximum length, and contains (state, action) pairs and their
corresponding (next_state, reward) result. As the number of episodes increases, the exploration rate decays exponentially as designed
and the agent will slowly switch to exploitation and execute actions from the CNN model output. Our DQN architecture is shown at Figure 1.
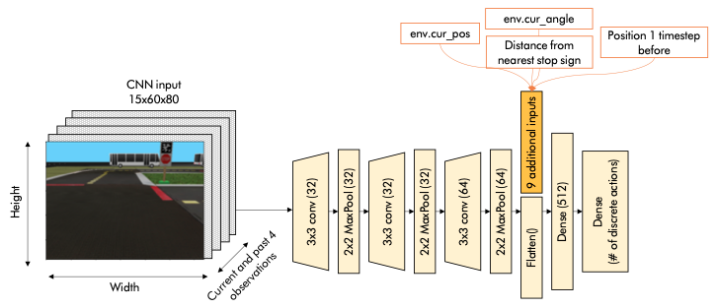
2. Choice of Input Extractions
We used a CNN architecture from the paper Almasi et. al [1].
The features extraction steps are similar: resizing input to 12.5% of the original DuckietownEnv observations,
and then normalizing pixel values from 0 to 1. We also used their proposed idea of concatenating past observations
to specially guide the agents at turns. There are some modifications which are furthed detailed in the report.
3. Action Representations
The DuckietownEnv accepts the discretized values of velocity in range [0,1] and streering angles spanning from \( [-\pi, +\pi] \).
In the simplest way, we give a large discretization bins of steering angles but the agent does not respond well to the traffic light
because of extremely low speed. We leveraged a pure-pursuit controller [2] to give us the picture of steering angles at the low speed.
At low speeds, the pure-pursuit controller outputs a huge range of steering angles from \( 10^{-3} \rightarrow 10^{-1}\). Thus we tried to
have a large discretized values around this range and this made the paths smoother when travelling at low speed.
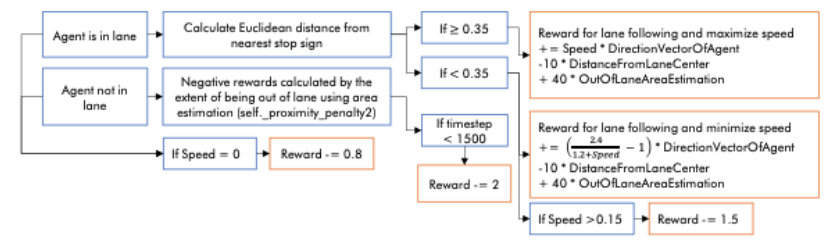
4. Reward Shaping
We use the default rewards provided by the DuckietownEnv. However, because of the requirement of low speed when nearing the traffic
light, we need to adjust to scale rightly with the default values. The reward shaping and the modification (the orange box) are in Figure 2.
For a detailed explaination, please refer to the report.
[1] Almási, P., Moni, R., & Gyires-Tóth, B. (2020). Robust Reinforcement Learning-based Autonomous Driving Agent for Simulation and Real World. Proceedings of the International Joint Conference on Neural Networks.